Dick, J., Nath, S., Peridis, C., Benjamin, E., Kolouri, S., & Soltoggio, A. (2024). “Statistical Context Detection for Deep Lifelong Reinforcement Learning.” Proceedings of Machine Learning Research, 274, 1013-1031. https://www.scopus.com/inward/record.uri?eid=2-s2.0-85219511357&partnerID=40&md5=44236f24c54c2e13e04ef41cc8a97b90
Context detection involves identifying different tasks within a continuous stream of data. These task labels are important for lifelong learning algorithms, helping to prevent a model from forgetting what it has learned. However, figuring out these task labels from ongoing data is a challenging problem. Most methods either assume simple, small-scale data or require a preliminary phase where task labels are learned upfront. Additionally, detecting changes in tasks based on rewards or transitions in data is harder because it relies on understanding the model’s actions, not just the data itself.
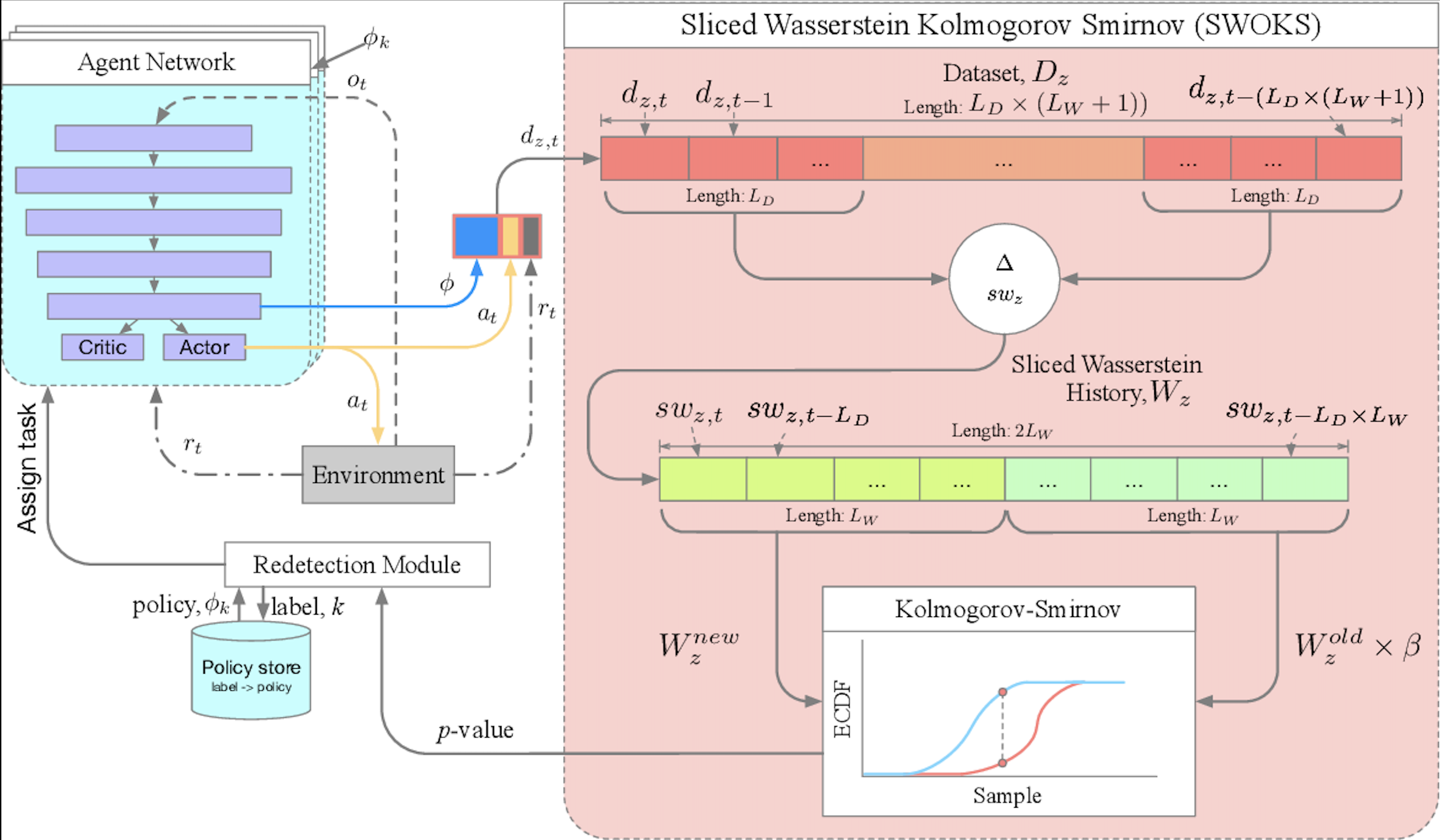
In this paper, we introduce a new method for learning both task labels and policies (the strategies the model uses to make decisions) in an online deep reinforcement learning setting. Our approach uses distance metrics, specifically Wasserstein distance, which measures how different past and current data are. These measurements allow us to perform statistical tests to assign task labels to sequences of experiences. We also introduce a “rollback” method to help the model learn multiple policies by ensuring that each policy is trained with the right data. This combination of task detection and policy training enables the model to improve continuously, without needing an external source to provide task labels. We tested our approach on two benchmarks, and the results show that it performs well compared to other context detection methods. Overall, our approach demonstrates that optimal transport methods can provide a clear and effective way to handle context detection and reward optimization in lifelong reinforcement learning.
Figure 1: Graphical representation of the SWOKS architecture.