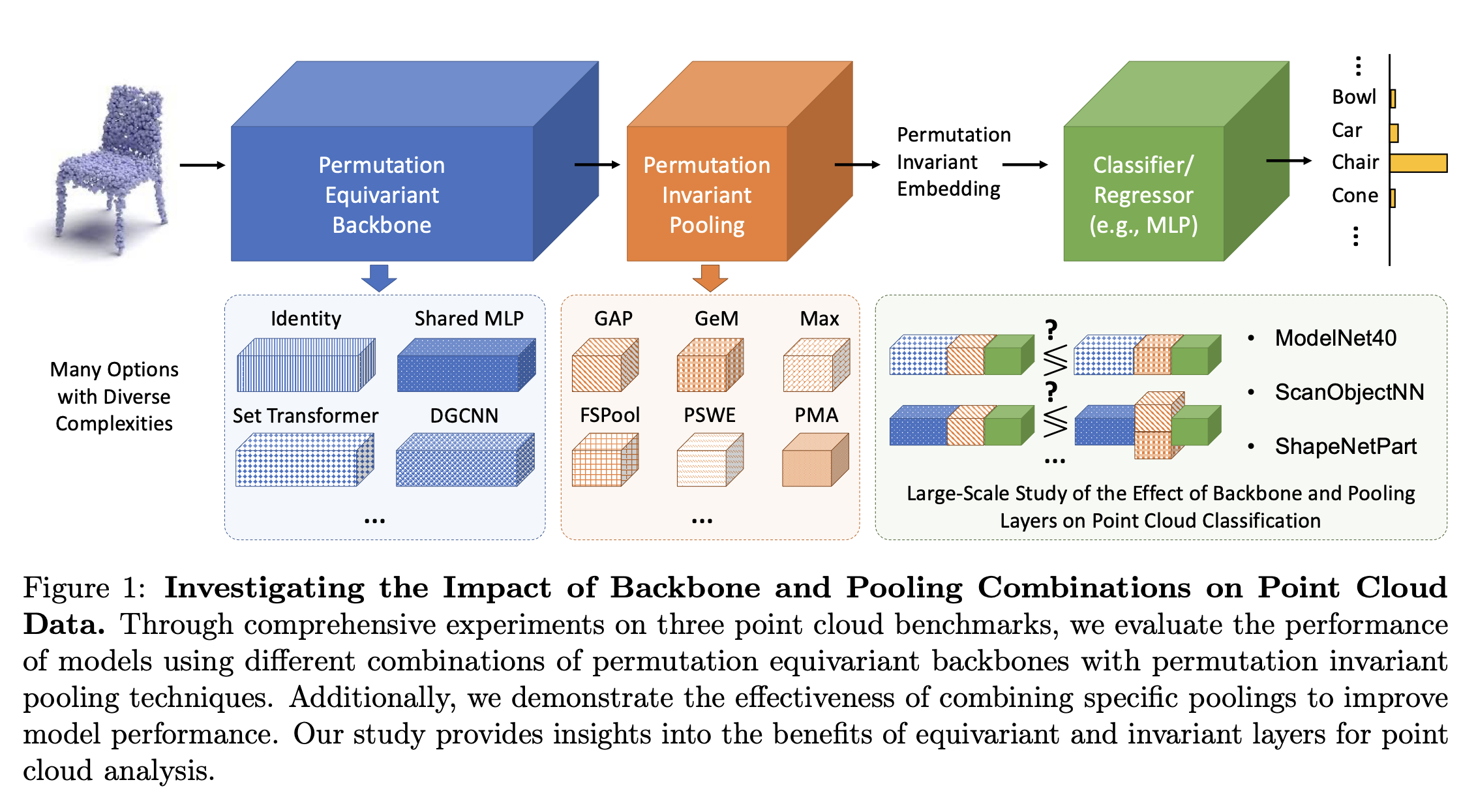
Machine learning models are increasingly being used to analyze point cloud data, which consists of unordered sets of points, such as 3D scans of objects. To effectively process this type of data, neural networks must be designed to ensure that their predictions remain the same regardless of the order in which the points appear. This is where permutation-invariant networks come in. While most research has focused on improving the core structure (or “backbone”) of these networks, the role of the pooling layer—a step that summarizes information—has often been overlooked.
In this study, we examine how different pooling methods impact the performance of these networks on three benchmark point cloud classification tasks. Our findings reveal that advanced pooling methods, such as transport-based or attention-based techniques, can significantly improve the performance of simple network backbones, though the effect is less pronounced for more complex architectures. We also find that even sophisticated networks benefit from better pooling when there is limited training data. Surprisingly, the choice of pooling method can have a greater impact on performance than increasing the size or complexity of the network itself. Additionally, combining two different pooling methods can further enhance accuracy.
Our study highlights the importance of selecting the right pooling strategy when designing machine learning models for point cloud data. By considering both the backbone and pooling layer together, researchers and practitioners can build more effective models. Our code is available at [GitHub link].