
Liu, X.; Bai, Y.; Lu, Y.; Soltoggio, A.; Kolouri, S. “Wasserstein task embedding for measuring task similarities.” Neural Networks, Volume 181, 2025, Article 106796, DOI: 10.1016/j.neunet.2024.106796.
Measuring the similarity between different tasks is important for various machine learning problems, such as transfer learning, multi-task learning, and meta-learning. Most existing methods for measuring task similarities depend on the architecture of the model being used. These approaches either rely on pre-trained models or use forward transfer as a proxy by training networks on tasks. The method proposed here is different—it is model-agnostic, does not require training, and can handle tasks with partially overlapping label sets. The technique involves embedding task labels using multi-dimensional scaling, then combining dataset samples with their corresponding label embeddings. The similarity between two tasks is then defined as the 2-Wasserstein distance between their updated samples. This method allows tasks to be represented in a vector space, where the distance between tasks can be calculated more efficiently. The results show that this approach significantly speeds up the comparison of tasks compared to other methods like the Optimal Transport Dataset Distance (OTDD). Through various experiments, the authors demonstrate that their method is closely linked to how knowledge transfers between tasks, showing strong correlations between their task similarity measure and actual transfer performance on image recognition datasets.
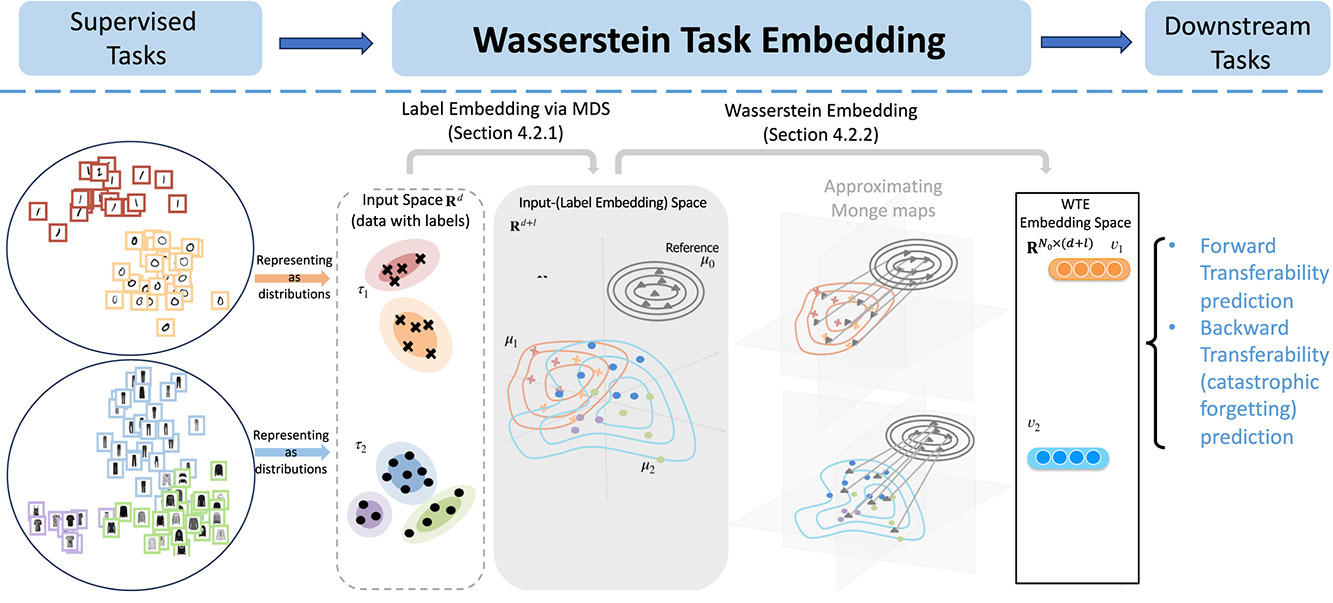
Fig. 1. Wasserstein Task Embedding framework. Given labeled task distributions and with input space , WTE first maps them into as probability distributions and by label embedding via MDS, then apply WE to get vectors and with respect to a fixed reference measure . Here is the size of reference set.